Prompt Playground
Open Playground in the sidebar — it's a top-level destination beside Dashboard, not nested under Agents (or navigate to /playground directly). The playground is enabled by default and hidden from the sidebar when dvara.flightdeck.playground.enabled=false. It is handy for quickly iterating on prompts, testing templates, or comparing how different models respond to the same input — without writing any client code.
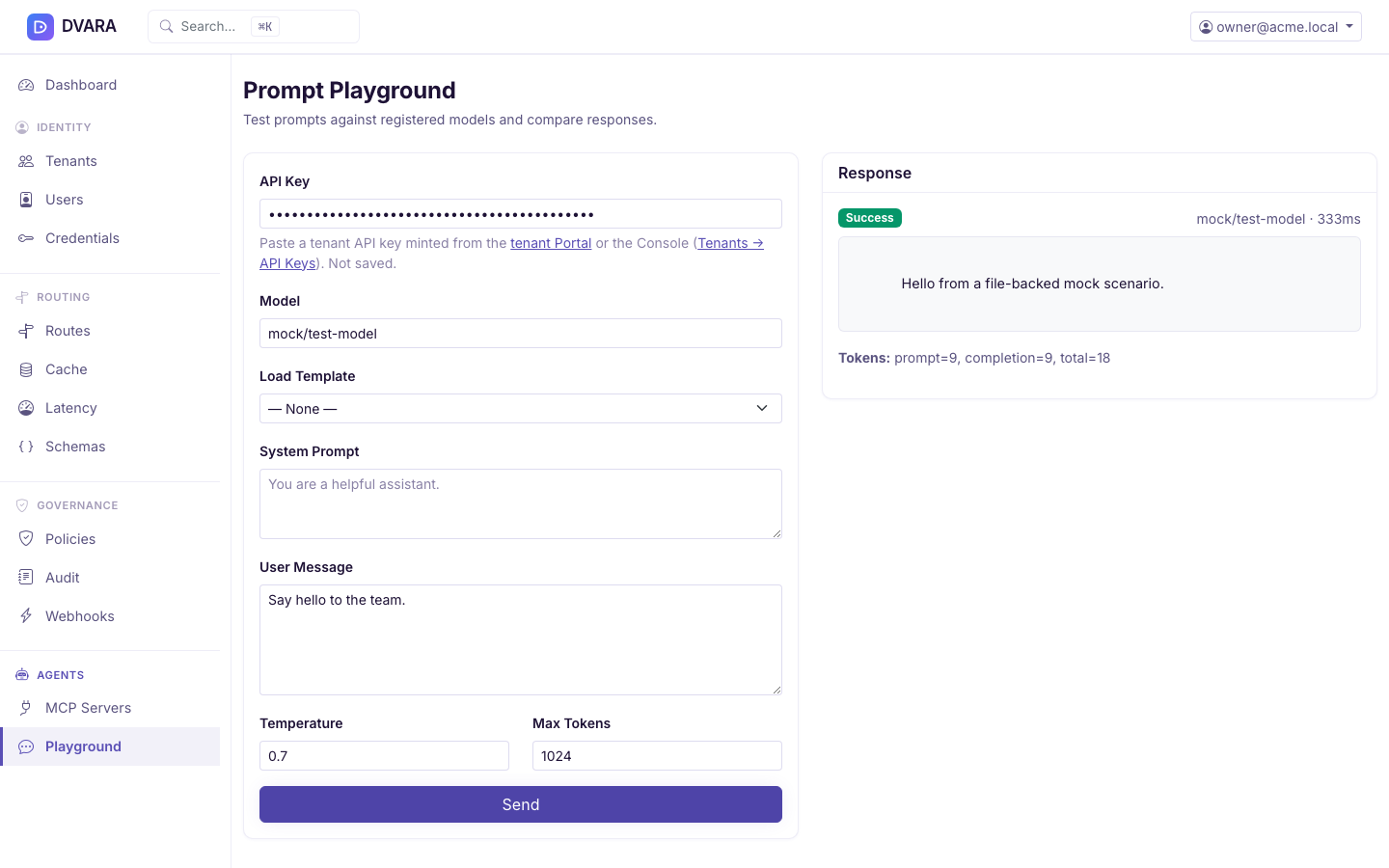
Each Send requires you to paste a tenant API key (gw_…) into the API Key field on the form. The key is not saved — there is no localStorage, no shared secret, no dropdown — so a new browser tab or a page reload clears the field. Mint a key from the tenant Portal (/portal/keys) or the Console (Tenants → API Keys → Create key) before testing. The playground proxies your call to the LLM Gateway exactly as any SDK would, so the request consumes the tenant's budgets, rate limits, and audit trail.
Configuration
The playground is enabled by default and can be disabled for production deployments:
| Property | Env var | Default | Description |
|---|---|---|---|
dvara.flightdeck.playground.enabled | DVARA_FLIGHTDECK_PLAYGROUND_ENABLED | true | Set false to disable the playground entirely |
When disabled, both the Console /playground and the Portal /portal/playground pages return 404 — the controllers are not registered at all, no endpoints are exposed.
Access — who can use the playground
The playground has two surfaces, gated to different audiences:
| URL | Layout | Roles |
|---|---|---|
/playground | Console (platform layout) | owner only — ad-hoc cross-tenant verification |
/portal/playground | Portal (tenant layout) | admin + developer — daily prompt-testing workflow |
Tenant viewer is excluded from both — the playground sends billed /v1/chat/completions calls and viewer is a read-only role by contract. Platform policy-admin and billing-admin are excluded from the Console version — policy-admin writes policies (not prompts) and billing-admin watches costs.
The two surfaces are functionally identical: same form, same template loader, same per-request tenant API key paste (not persisted, no localStorage). The split is to give each audience a familiar layout — platform owners stay in the Console; tenant developers land in the Portal next to their own keys, usage, and team.
Features
- Model selector — type any registered model name (e.g.
gpt-4o,claude-sonnet-4-5,ollama/llama3.2) - Template loader — pick an active prompt template to populate the system prompt and user message fields
- System prompt editor — optional system message
- User message editor — the prompt to test
- Controls — adjustable temperature (0–2) and max tokens (1–128 K)
- Send — live request to the LLM Gateway. The response panel shows generated text, token usage, and latency.
Side-by-side model evaluation
For structured comparison across models — A/B/C/D the same prompt against gpt-4o, claude-3-opus, gemini-1.5-pro before pinning a route — use the Eval pipeline (POST /v1/admin/eval/suite?model=X). The eval surface carries the use case the playground compare endpoint used to serve: parallel multi-model runs against a golden-prompt corpus, persisted EvalReport rows, drift detection.
For ad-hoc side-by-side without a corpus, open the playground in two browser tabs with different models — it's the same input form, run twice. Two tabs is cheaper than maintaining a separate compare API surface.