Prompts & Evals
DVARA's prompt management surface has four tightly related features:
- Prompt templates — versioned, variable-substituted prompts with a lifecycle (DRAFT → ACTIVE → ARCHIVED).
- Prompt experiments — A/B tests across template variants with per-variant metrics.
- Golden prompts + model fingerprinting + drift reports — periodically re-run a fixed prompt against a model to catch silent model changes.
- Eval pipeline — batch-run a suite of prompts against a model and score the results.
All four are admin-only surfaces.
Prompt templates
Open Prompts → Templates in the sidebar (or use the Automation API at /v1/admin/prompts).
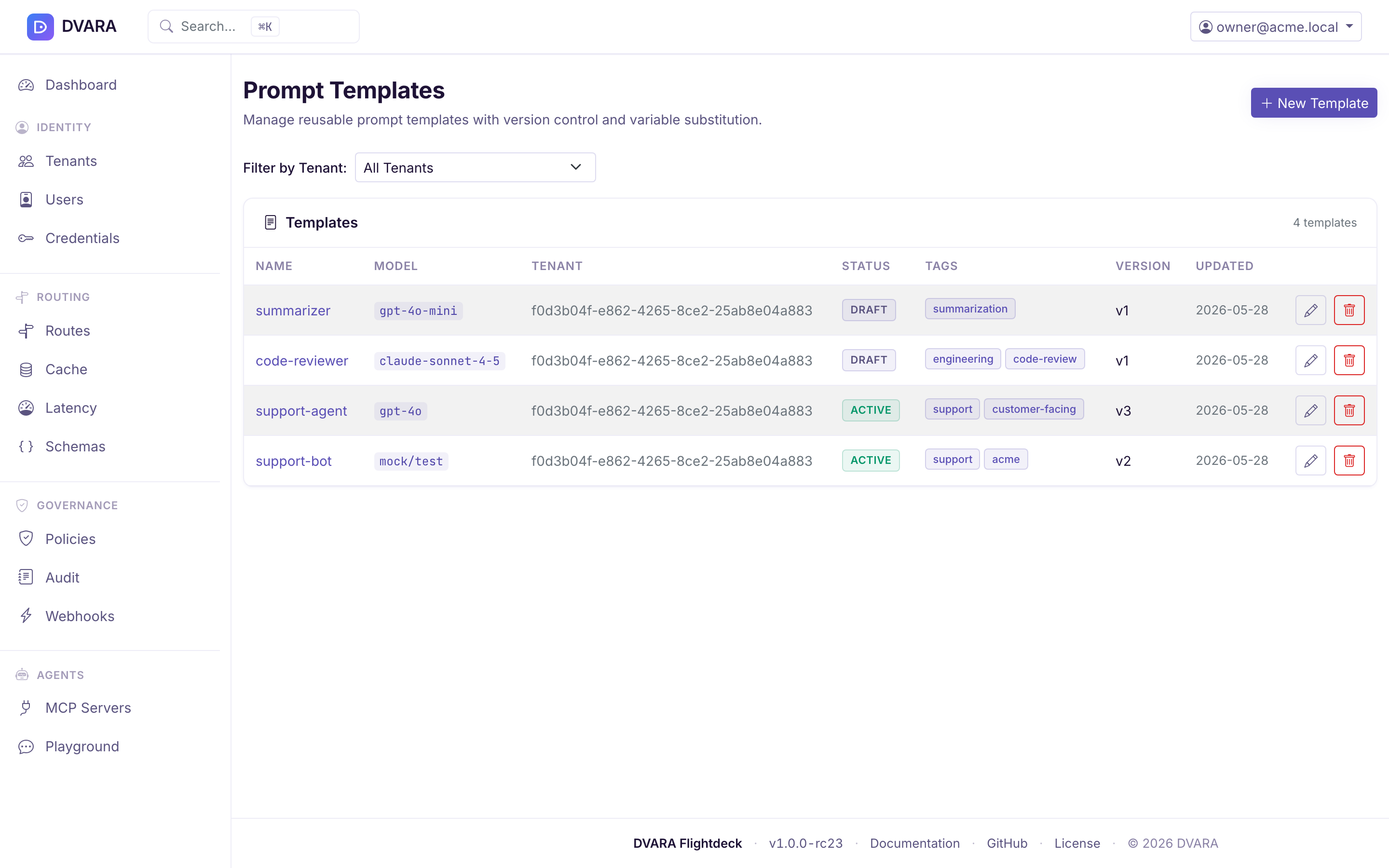
Template list
Lists every template with ID, name, tenant, status badge (DRAFT / ACTIVE / ARCHIVED), version, and last-updated timestamp. Use the Tenant dropdown filter to narrow the list.
Create / edit template
Click New Template to create a template with:
- Name — human-readable template name
- Tenant ID — scope to a tenant (blank = global)
- System prompt — optional system message, with
{{placeholders}}for variables - User prompt — the main prompt body, also with
{{placeholders}} - Status — DRAFT, ACTIVE, or ARCHIVED
Variables are auto-extracted from {{name}} tokens on save. A template starts in DRAFT status; only ACTIVE templates can be referenced from the Playground or request.metadata["prompt_template_id"] on chat completions.
Render preview
Click Preview (or call POST /v1/admin/prompts/{id}/render) with a map of variable values to see the rendered system / user text before saving. The render endpoint is also how the playground's template loader works.
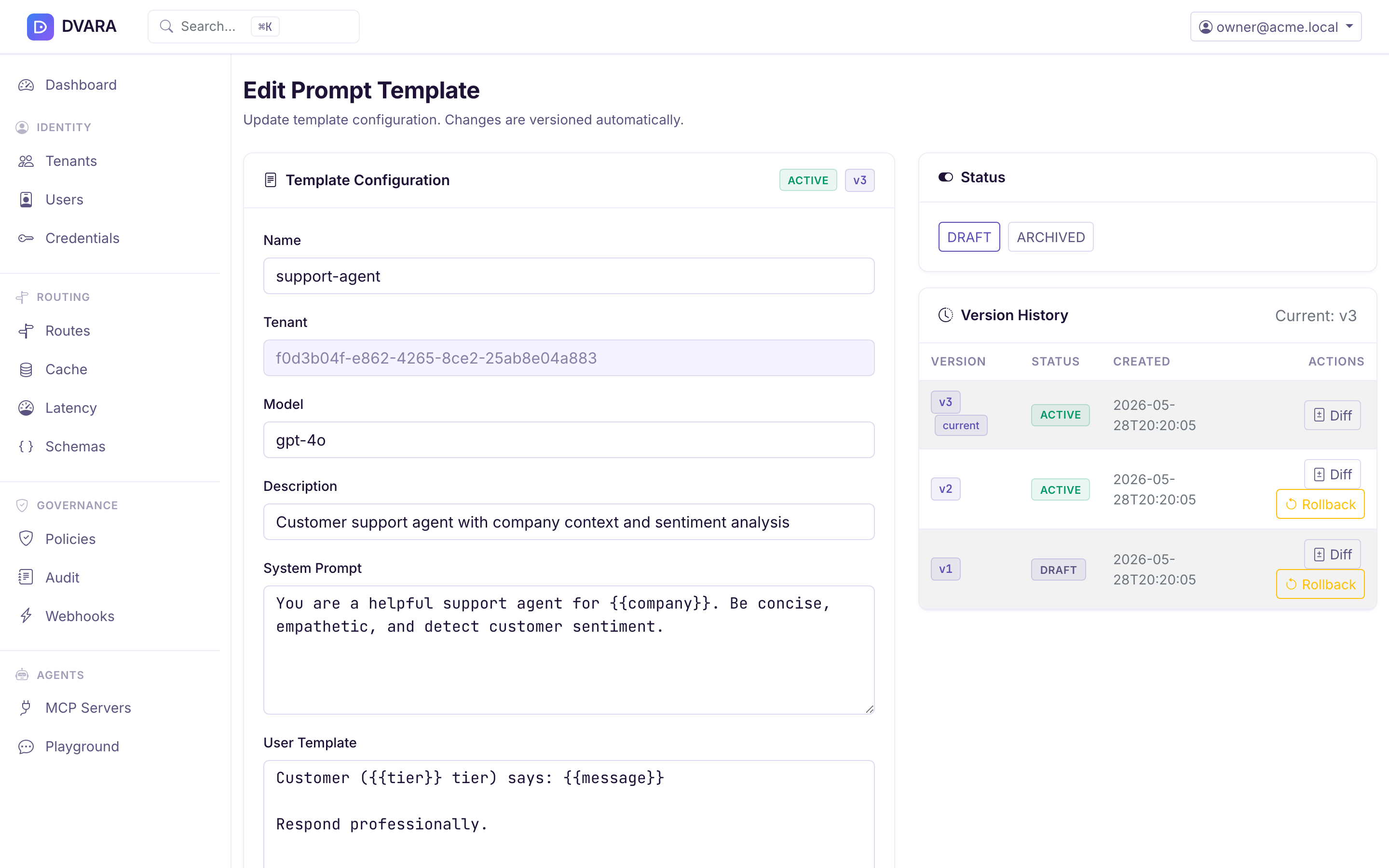
Version history & rollback
Same mechanism as routes and policies: last 10 versions retained, diff viewer highlights changed fields, rollback creates a new version with the restored content.
Error codes: PROMPT_TEMPLATE_NOT_FOUND (404), PROMPT_TEMPLATE_NOT_ACTIVE (400), PROMPT_VARIABLE_MISSING (400), PROMPT_VERSION_NOT_FOUND (404), INVALID_TEMPLATE_STATUS (400).
Prompt experiments
Open Prompts → Experiments in the sidebar.
An experiment is an A/B test across multiple template variants. Each variant gets a weight (percentage of traffic routed to that variant), and the weights must sum to 100. DVARA tracks per-variant request count, token usage, cost, latency, and error rate in a dedicated metrics collector.
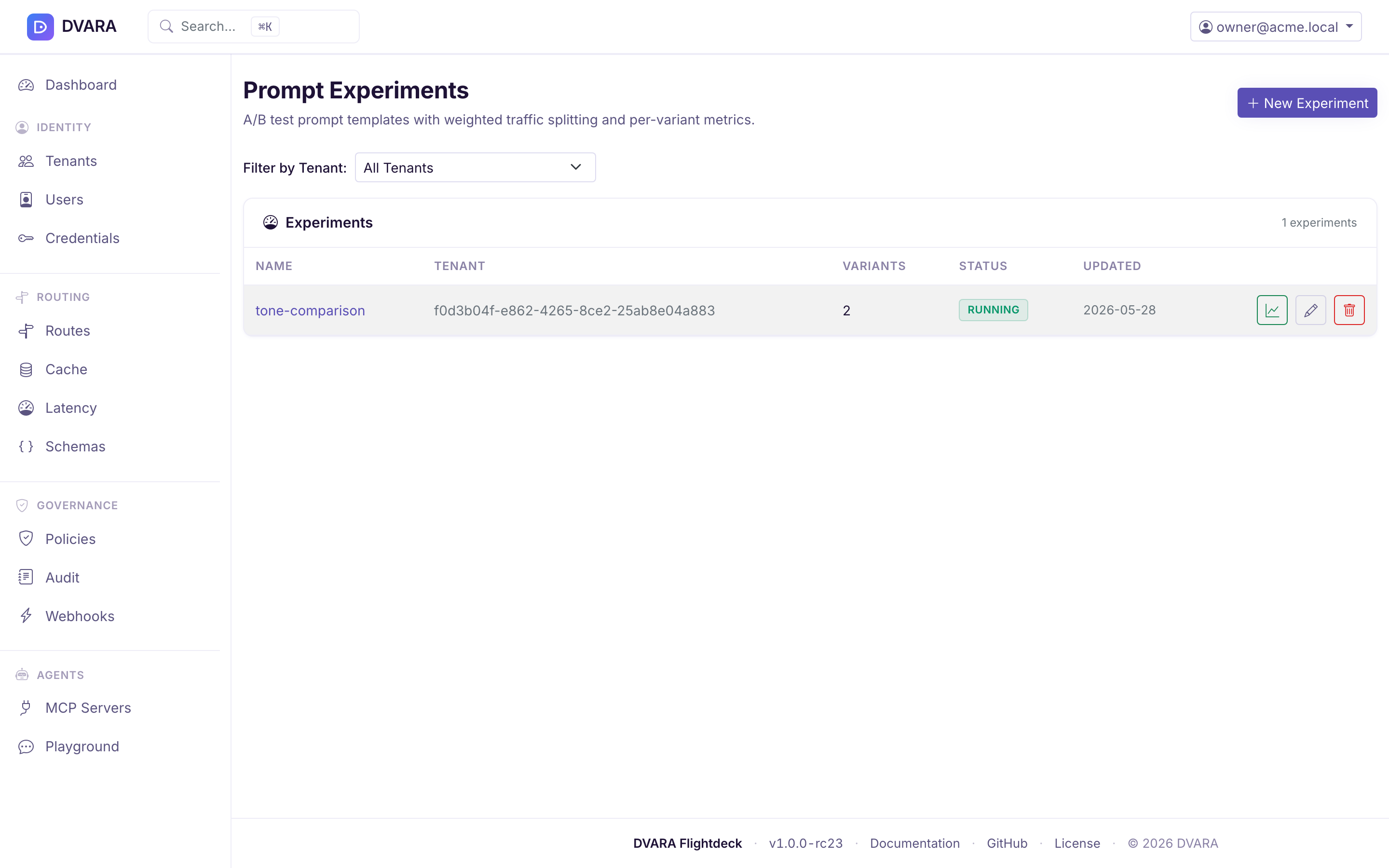
Experiment list
Lists every experiment with ID, name, tenant, status (DRAFT / RUNNING / PAUSED / COMPLETED), variant count, and start time. Filter by tenant.
Create / edit experiment
- Name — identifier
- Tenant ID — scope to a tenant (blank = global)
- Variants — a list of
{templateId, weight}pairs. Weights must total 100. DVARA rejects lopsided or incomplete configurations. - Status — DRAFT to start; transition through RUNNING → PAUSED → COMPLETED.
Lifecycle
- DRAFT — editable, no traffic is routed
- RUNNING — traffic is split by weight; metrics collected
- PAUSED — traffic reverts to the default template, metrics preserved
- COMPLETED — terminal; read-only
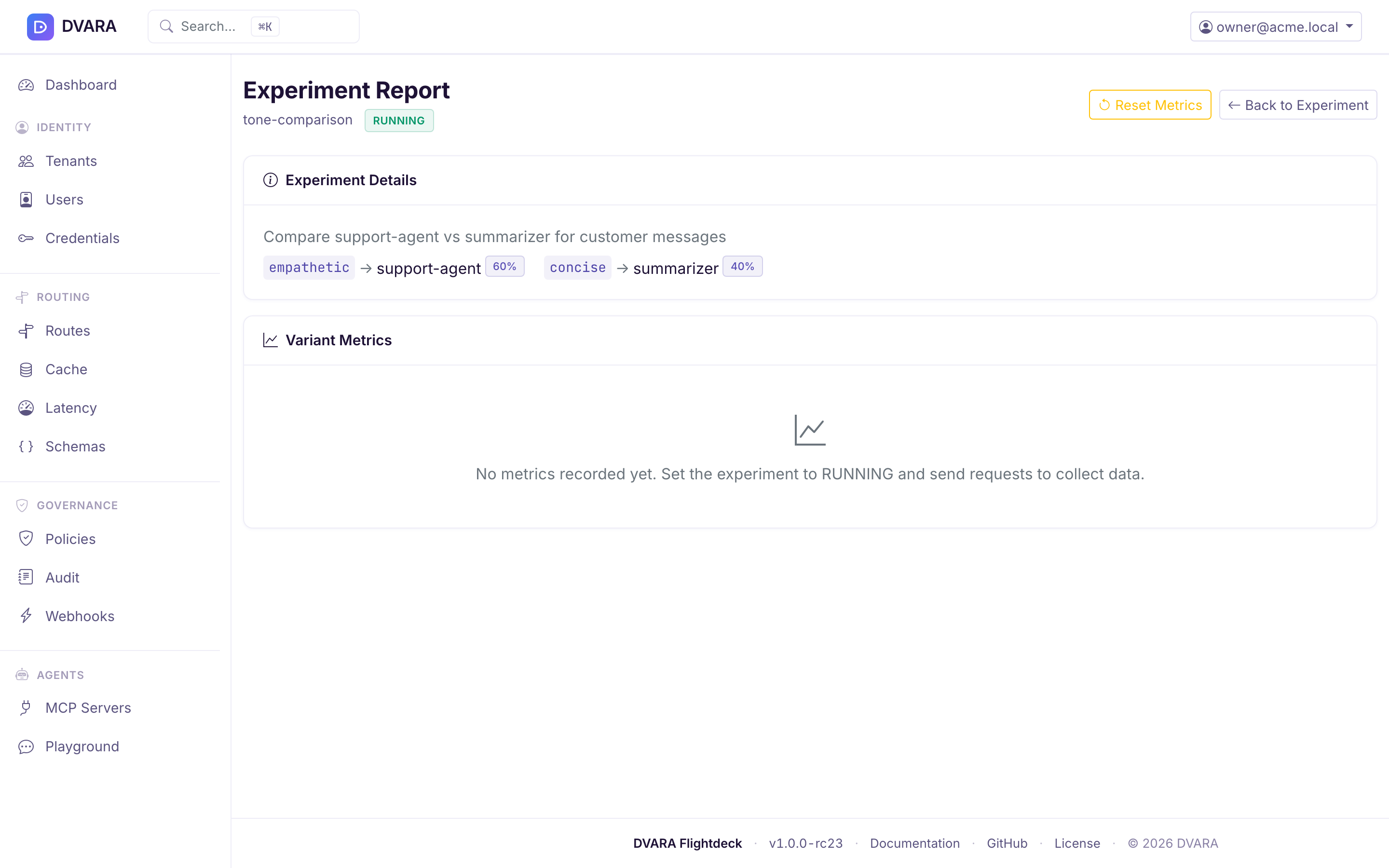
Metrics report
GET /v1/admin/prompts/experiments/{id}/report returns a per-variant snapshot: requests, tokens (in/out), total cost, average latency, error rate. The UI renders this as a side-by-side comparison table.
Error codes: PROMPT_EXPERIMENT_NOT_FOUND (404), PROMPT_EXPERIMENT_NOT_RUNNING (400 on metric submissions when the experiment is not in RUNNING state).
Golden prompts & model fingerprinting
Golden prompts are the canaries in your coal mine for silent model changes. DVARA periodically runs a fixed prompt against a model, hashes the response (and a feature-extracted fingerprint), and compares it to a baseline. When the fingerprint diverges beyond a threshold, a drift report is generated.
Open Prompts → Golden Prompts in the sidebar.
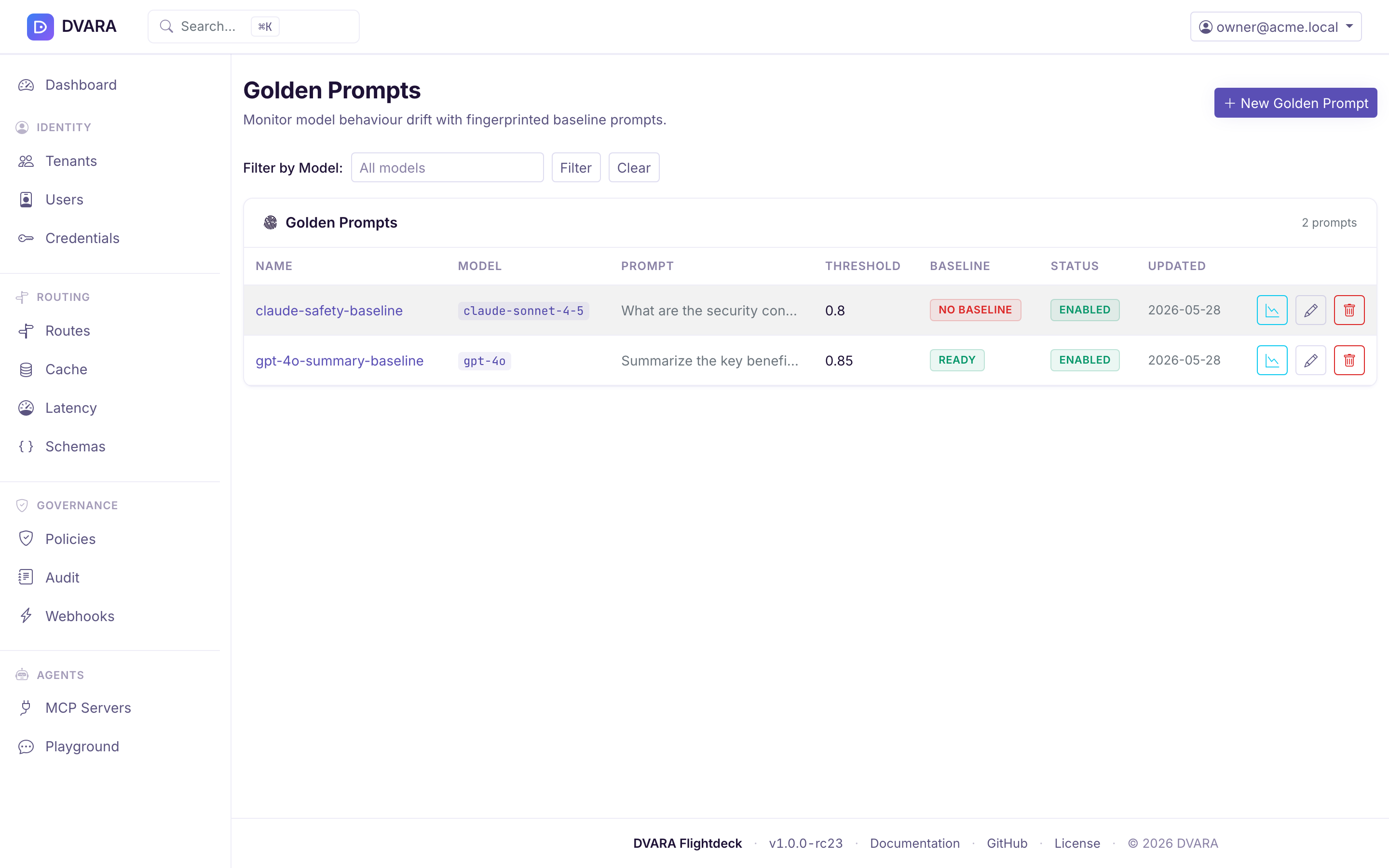
Golden prompt list
Lists every golden prompt with ID, name, model, last fingerprint timestamp, drift status badge, and actions. Filter by model.
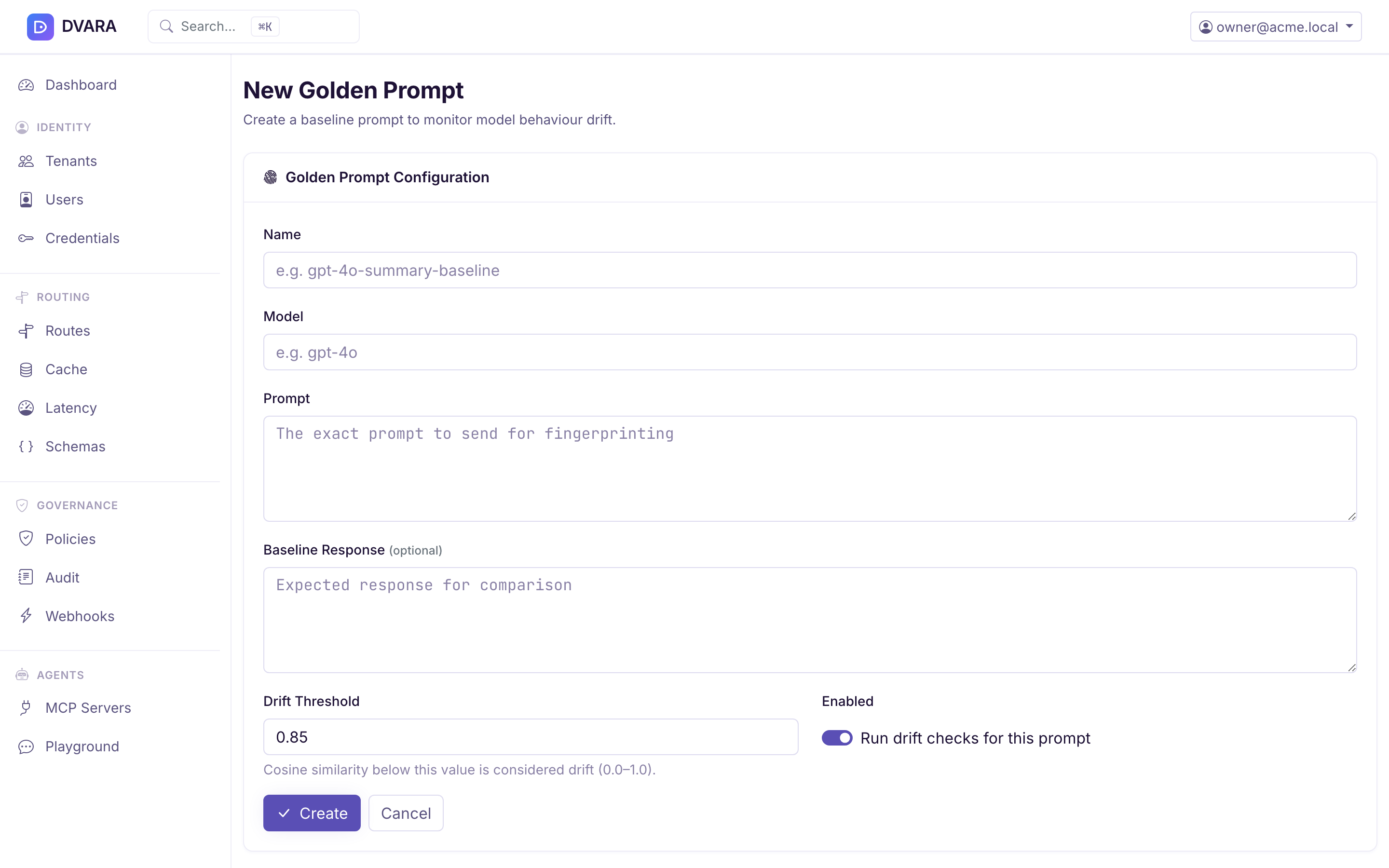
Create golden prompt
- Name — identifier
- Model — the exact model name to test (e.g.
gpt-4o-2024-08-06) - Prompt — the canary prompt body
- Expected response — optional, used for stricter match
- Similarity threshold — cosine similarity below which a result is considered drifted (default: 0.85)
Trigger a fingerprint check
Click Check Now (or POST /v1/admin/golden-prompts/{id}/fingerprint) to immediately re-run the prompt and compute a new fingerprint. The response includes the current and baseline fingerprints, similarity score, and drift flag.
Drift report
GET /v1/admin/golden-prompts/{id}/drift?days=7 returns the drift history for the last N days (default: 7), including a time series of similarity scores and any events where the threshold was breached.
Under the hood, DVARA vectorizes each response with an embedding model, stores the resulting fingerprint alongside the baseline, and computes cosine similarity on every check. When the similarity drops below the configured threshold, a drift event is recorded.
Eval pipeline
Open Prompts → Eval Prompts (or Eval Reports) in the sidebar.
The eval pipeline is the batch counterpart to golden prompts — run a suite of prompts against a model and produce a scored report rather than a single drift event. Typical use cases: regression-testing a prompt template before promoting it to ACTIVE, or qualifying a new model before routing production traffic.
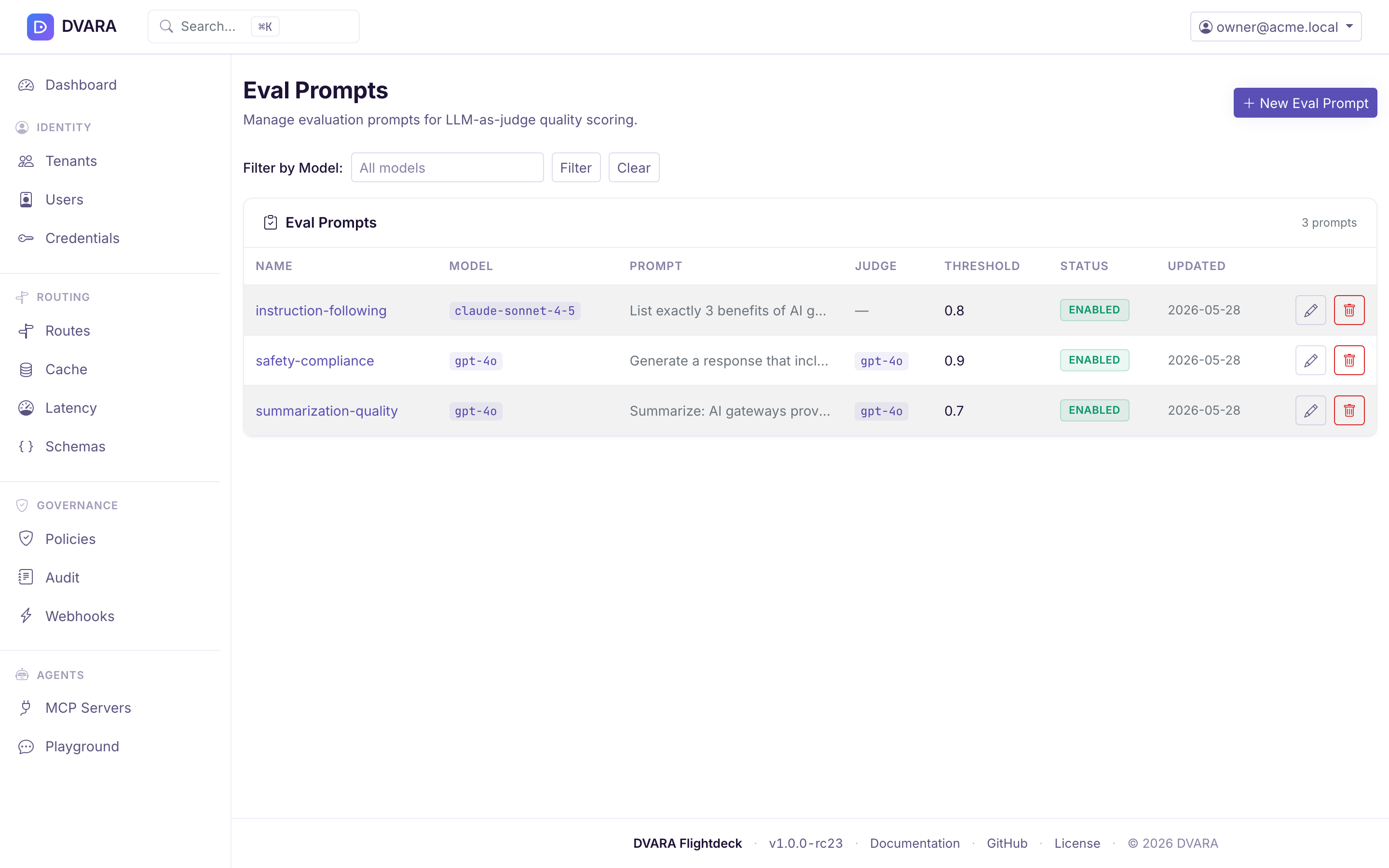
Eval prompts
CRUD at /v1/admin/eval/prompts. Each eval prompt has:
- Name — identifier
- Prompt — the input to send
- Expected — the expected output (exact match or semantic similarity)
- Scoring —
exact-match,embedding-similarity, or custom
Running an eval
- Single eval:
POST /v1/admin/eval/{id}/run— runs one prompt against a specified model and returns the scored result. - Suite run:
POST /v1/admin/eval/suite?model=gpt-4o— runs every configured eval prompt against the given model and produces a report with pass / fail counts, scores, and per-prompt results.
Reports
GET /v1/admin/eval/reports— list all eval reports, optionally filtered by?model=GET /v1/admin/eval/reports/{id}— detailed view of a single reportGET /v1/admin/eval/reports/model/{model}— reports for a specific model in a time range
The eval runner fans out prompts in parallel, respects each model's context window, and aggregates scores into a single report. Reports and per-prompt results are persisted so you can compare runs across models and over time.
API summary
| Endpoint | Purpose |
|---|---|
POST /v1/admin/prompts | Create prompt template |
GET /v1/admin/prompts | List templates (filter by ?tenant_id=) |
PUT /v1/admin/prompts/{id} | Update template (increments version) |
POST /v1/admin/prompts/{id}/status | Change DRAFT/ACTIVE/ARCHIVED |
POST /v1/admin/prompts/{id}/render | Preview rendered template |
POST /v1/admin/prompts/{id}/rollback | Rollback to a prior version |
POST /v1/admin/prompts/experiments | Create experiment |
POST /v1/admin/prompts/experiments/{id}/status | Lifecycle transitions |
GET /v1/admin/prompts/experiments/{id}/report | Per-variant metrics |
POST /v1/admin/golden-prompts | Create golden prompt |
POST /v1/admin/golden-prompts/{id}/fingerprint | Trigger fingerprint check |
GET /v1/admin/golden-prompts/{id}/drift | Drift history |
POST /v1/admin/eval/prompts | Create eval prompt |
POST /v1/admin/eval/{id}/run | Run a single eval |
POST /v1/admin/eval/suite?model=X | Run the full eval suite against a model |
GET /v1/admin/eval/reports | List eval reports |
Every write through the Automation API emits an audit event so a compliance trail of prompt and eval changes exists alongside the Console UI's own emit: PROMPT_TEMPLATE_CREATED / _UPDATED / _STATUS_CHANGED / _ROLLED_BACK / _DELETED, PROMPT_EXPERIMENT_CREATED / _UPDATED / _STATUS_CHANGED / _RESET / _DELETED, GOLDEN_PROMPT_CREATED / _UPDATED / _DELETED / _FINGERPRINTED, EVAL_PROMPT_CREATED / _UPDATED / _DELETED / _RUN, and EVAL_SUITE_RUN.